This website is still under construction. We keep adding new results, so please come back later if you want more.
This website presents additional material and experiments around the paper Continuous descriptor-based control for deep audio synthesis.
Despite significant advances in deep models for music generation, the use of these techniques remains restricted to expert users. Before being democratized among musicians, generative models must first provide expressive control over the generation, as this conditions the integration of deep generative models in creative workflows. In this paper, we tackle this issue by introducing a deep generative audio model providing expressive and continuous descriptor-based control, while remaining lightweight enough to be embedded in a hardware synthesizer. We enforce the controllability of real-time generation by explicitly removing salient musical features in the latent space using an adversarial confusion criterion. User-specified features are then reintroduced as additional conditioning information, allowing for continuous control of the generation, akin to a synthesizer knob. We assess the performance of our method on a wide variety of sounds including instrumental, percussive and speech recordings while providing both timbre and attributes transfer, allowing new ways of generating sounds.
We would like to thank our reviewers for their helpful suggestions and comments on our article and this accompanying website.
Examples contents
Additional details
Code and implementation
Audio reconstruction
First, we compare the quality of our models to perform pure reconstruction of an input from the test set, depending on whether it uses conditioning (C-) or faders (F-). Those models were computed on the Darbuka and NSynth datasets.
| Darbuka | Original | Reconstruction |
|---|---|---|
| C-Rave | ||
| F-Rave |
| NSynth | Original | Reconstruction |
|---|---|---|
| C-Rave | ||
| F-Rave |

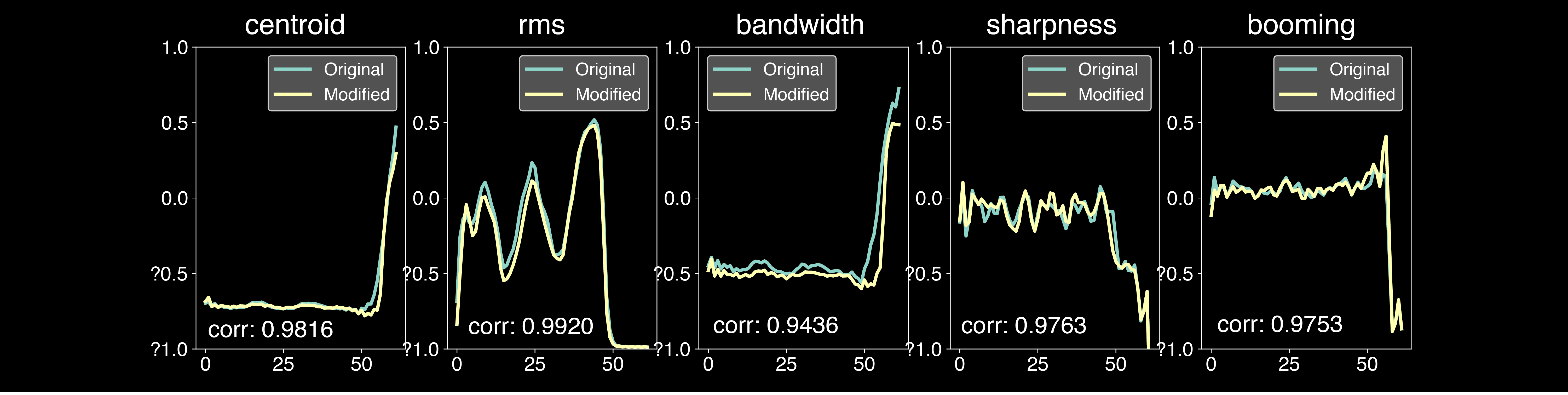
In order to exploit the artistic potential of our method, we performed extended experiments on other datasets than those presented in the paper. We selected a Japanese voices dataset to extend the performance of SC09, which may be limited for attribute exchange or timbre transfer, and we selected a violin dataset to get rid of the monophonic and short note of Nsynth. For the SC09, Japanese and Violin datasets, we only present the results of our proposed F-Rave model. We display the analysis of the additionnal datasets below.
| Japan | Original | Reconstruction |
|---|---|---|
| Violin | Original | Reconstruction |
|---|---|---|
| SC09 | Original | Reconstruction |
|---|---|---|
Single attribute control
In this section, we further analyze how different methods behave in terms of control quality. To do so, we trained a separate model for each of the 6 descriptors, and a model for all descriptors at once (termed C-RAVE (m.) and F-RAVE (m.)). We analyze the correlation between target and output attributes when changing a single descriptor.
Attributes coming from classical synthesizers control signals
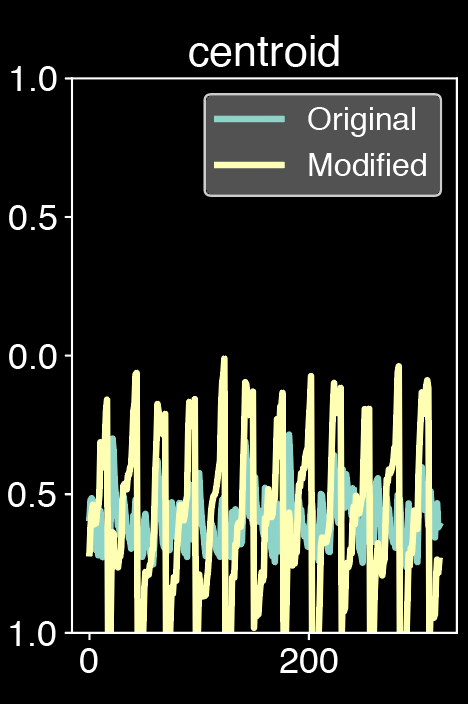
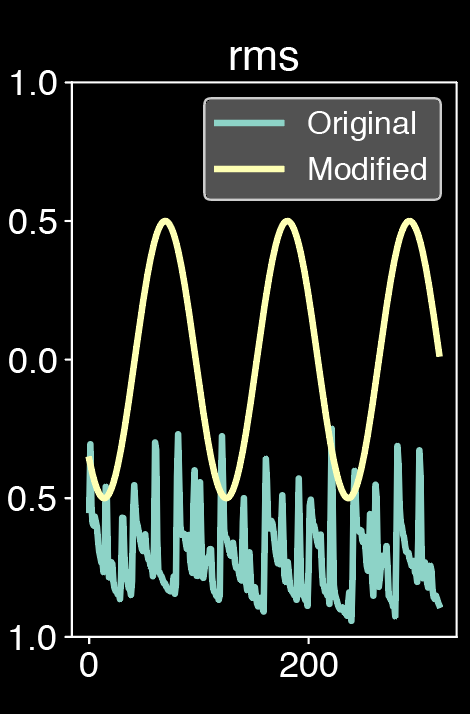
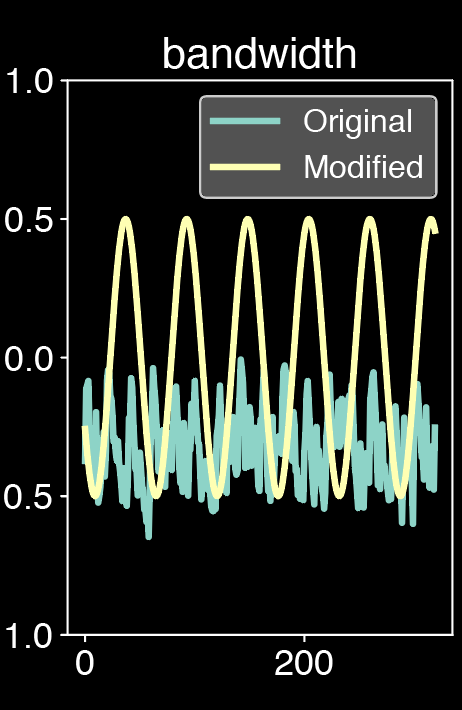
As experiments, we first simulates the behavior faders sliding by taking rampes up, rampes down, sinusoides and sawtooth as modulators. Those are the classic control available on traditionnal synthesizers. The results might be strongly alterated as these controls may not be the most appropriate for attributes modification. They sometimes sound unnatural and some sonic artifacts (such as distortion or flanger effect) might appear when incoming controls are very different from the training data. Better audio results could be achieved by applying more subtle and tailored controls to better match the input: curve shifting in order to stay in the amplitude range of the input, modulation in order to better fit the input, filtering or the control or even parts editing. The goal would be to obtain adapted features curves in order to be closer to the original curves. This work will be part of future work.
Original sound:

Modulated sound from classical Eurorack synthesizers signals, we slide the attributes one by one:
 |
 |
 |
 |
 |
|---|---|---|---|---|
Attributes coming from an other sample of the dataset
Here, we select as modulators the attributes of other samples coming from the same dataset. The modification of attributes are clearly heard and it appears that the RMS and the centroid have a strong influence on the sound generation whereas the sharpness and the boominess have a more subtle effect. However, taking the attributes from an other sample of the dataset quickly degrades the quality on the Japanese dataset and on the violin. This is due to the abrupt change of attributes which can easily be outside of the range of the original attributes. Similarly to the section above, the best would be to adapt the feature to the input in order to obtain more natural sounds.
| Dataset | Darbouka | Japanese | Violin |
|---|---|---|---|
| Original | |||
| Modulator | |||
| RMS | |||
| Centroid | |||
| Bandwidth | |||
| Sharpness | |||
| Boominess |
Timbre transfers
In this section we take the model trained on a particular dataset and we pass it a sample from an other dataset, performing timbre transfer.
| Source | Audio | Target | Audio |
|---|---|---|---|
| Violin | Darbouka | ||
| Violin | Japanese | ||
| Darbouka | Japanese | ||
| Darbouka | Violin | ||
| Japanese | Dabouka | ||
| Japanese | Darbuka | ||
| Japanese | Violin | ||
| Japanesea | Violin |
Additionnal details
Comparison with DDSP
Some methods such as the DDSP families are able to perform reconstruction and timbre transfer and could have potentially be a good candidate for a baseline to our work instead of RAVE. However, we believe that the monophonic nature of DDSP is an impediment to an artistic endeavor, especially as our model aims to be embedded into a hardware musical tool. Furthermore, DDSP provides explicit control whereas our work is based on implicit control. In our past experiments with DDSP, we have noticed that the importance of already existing external conditioning (f0, loudness) would render the latent space almost meaningless (having no impact on the generated sounds). Therefore, we believe that DDSP would not be able to take into account our implicit descriptors’ conditioning, hence not being a sound choice as a baseline. However, we performed additional experiments with DDSP as a baseline with NSynth dataset and we display here a straightforward comparison table between our two baseline, RAVE and DDSP.
After the submission, we continued to work on our approach for artistic applications and performed hyperparameters tuning which have significantly improved the overall performance. These additional experiments have been conducted with the latest version.
| Model | JND | Mel | mSTFT |
|---|---|---|---|
| Fader-DDSP | 0.39 | 36.69 | 7.10 |
| F-RAVE | 0.24 | 14.58 | 4.93 |
Table A. Comparison of the reconstruction provided by Fader-DDSP and F-RAVE for multi-attribute training
| Model | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Fader-DDSP | 0.78 | 0.73 | 0.67 | 0.61 |
| F-RAVE | 0.83 | 0.78 | 0.75 | 0.75 |
Table B. Comparison of control provided by Fader-DDSP and F-RAVE when changing one, or a set of multiple descriptors (up to 4)
| Model | JND | Mel | mSTFT | Centroid |
|---|---|---|---|---|
| C-DDSP | 0.28 | 36.65 | 7.14 | 0.52 |
| F-DDSP | 0.39 | 36.69 | 7.10 | 0.47 |
| C-RAVE | 0.235 | 13.92 | 4.88 | 0.74 |
| F-RAVE | 0.240 | 14.58 | 4.93 | 0.78 |
Table C. Comparaison of the reconstruction for mono attribute training (RMS).
| Model | RMS | Bandwidth | Sharpness | Booming | Mean |
|---|---|---|---|---|---|
| C-DDSP | 0.62 | 0.54 | 0.69 | 0.63 | 0.60 |
| F-DDSP | 0.59 | 0.47 | 0.68 | 0.53 | 0.55 |
| C-RAVE | 0.72 | 0.64 | 0.62 | 0.73 | 0.69 |
| F-RAVE | 0.76 | 0.66 | 0.72 | 0.77 | 0.73 |
Table D. Comparison of the control provided by various models on different descriptors for mono-attribute.
In the following, we present the evaluation on our model FRAVE on several dataset that were not presented in our paper.
Japanese dataset
We pursued our experiments on speech with the Japanese speech corpus of Saruwatari Lab , University of Tokyo, a Japanese text (transcription) and reading-style audio. This 48kHz dataset contains 10h of speech by native Japanese female speaker.
| JND | Mel | STFT | Corr | L1 | Cycle-jnd |
|---|---|---|---|---|---|
| 0.135 | 0.917 | 4.714 | 0.775 | 0.244 | 0.121 |
We beleive this dataset is more adapted to attribute control and timbre transer and has more artistic potential than SC09 dataset which has been largely used and massively evaluated.
Violin dataset
We pursued our experiments on instrumental sounds with an internal dataset of violin. This 44100Hz dataset contains 10h of recording of violin(s) playing.
| JND | Mel | STFT | Corr | L1 | Cycle-jnd |
|---|---|---|---|---|---|
| 0.226 | 12.998 | 7.591 | 0.791 | 0.252 | 0.136 |
We think this dataset composed of melodies played by one or several violin is more adapted to artistic purpose than te monophonic Nsynth.
Hardware embedding
Finally, in order to evaluate the creative quality of our model as a musical instrument, we introduce the NeuroRave, a prototype hardware synthesizer that generates music using our F-RAVE model. The interface is a module following the Eurorack specifications in order to allow for CV and gate interactions with other classical Eurorack modules. More precisely, alongside with the OLED screen and a RGB LED encoder button, our module features four CVs and two Gates. The software computation is handled by a Jetson Nano, a mini-computer connected to our front board, which provides a 128-core GPU alongside with a Quad-core CPU.
User interaction
The main gate input triggers the generation of the sound, while one of the CV handle the first latent dimension of the prior. The left CVs handle the sliding of the attributes, one by one. The last gate offers a more experimental control as it triggers the modification of all attributes at the same time, similarly to a macro-control.
Code
The full open-source code is currently available on the corresponding GitHub repository. Code has been developed with Python 3.7. It should work with other versions of Python 3, but has not been tested. Moreover, we rely on several third-party libraries that can be found in the README.
The code is mostly divided into two scripts train.py and evaluate.py. The first script train.py allows to train a model from scratch as described in the paper. The second script evaluate.py allows to generate the figures of the papers, and also all the supporting additional materials visible on this current page.
Our code will be released under acceptance